As I’ve written about before, I am still working on transcribing the last part of my manuscript from handwritten pages to digital text. Because I am currently very busy with other things in my life, this has been going very slowly. Therefore, I’ve tried to used technology to get the job done faster. With mixed results.
I’ve been experimenting with the Transkribus service to try and train a machine learning algorithm to recognise my handwriting. After several weeks of working on this sporadically, I managed to get my model’s CER down to 5%. That means that 5% of all transcribed characters are wrong. That does not sound like a lot, but it turns out that anything more than 1% errors with stuff like this means that you still have a hell of a lot of work to do to get the results into a usable state. Once again, it turns out that, when you actually look at what people usually term “artificial intelligence”, it tends to fall short of the miracles the PR people promise.
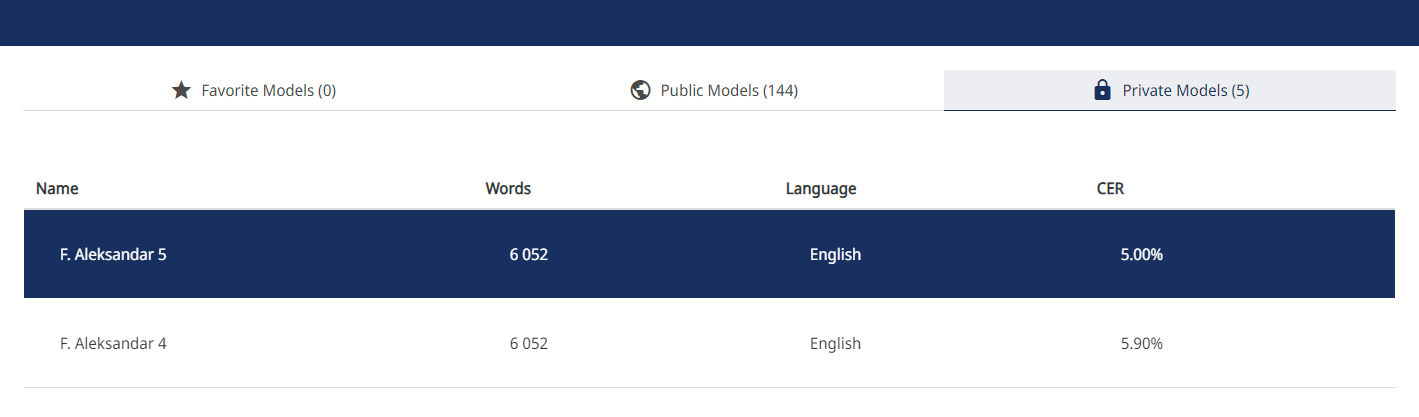
For now, I have given up to improve this model and will work with what I have for now. Which means I currently stand at 53 of 108 fully transcribed pages and 19 additional pages in a raw state as a result of the algorithmically-based transcription.
I am not happy with this progress at all and, from now on, will try to regularly set time aside to get this chore finished, but due to the vagaries of life as a freelance journalist, I can’t promise anything. I will update you on my progress, though. However slow it might be.